
Research Areas
Distributed Machine Learning:
Signal Processing:
Communication:
Distributed optimization
Image Source: http://awildduck.com
The goal of decentralized optimization over a network is to optimize a global objective formed by a sum of local (possibly non-smooth) convex functions using only local computation and communication.
This problem arises in various application domains, including distributed tracking and localization, multi-agent co-ordination, estimation in sensor networks, and large-scale optimization in machine learning. Common to these problems is the necessity for completely decentralized computation that is locally light—so as to avoid overburdening small sensors or flooding busy networks—and robust to periodic link or node failures. With the emergence in recent years of big data paradigms, decentralized optimization algorithms have received considerable interest in the literature.
A distributed optimization problem of particular relevance is the one in which the global objective function is obtained as the sum of a local convex functions. Originally considered by Tsitsiklis et al., this problem is broadly referred to as the consensus problem.
A number of distributed sub-gradient methods have been proposed to solve the consensus problem such as the distributed dual averaging and distributed alternating direction method of multipliers algorithms.
In these algorithms, generally speaking, nodes start from an initial estimate of the optimal point from a local function and exchange information regarding the gradient of their local estimates. Upon receiving the communication from the neighboring nodes, each node updates its estimate using a linear combination of the estimates of its neighbors and the gradient of its local function. In the literature, a number of variations of this algorithm have been considered, such as continuous time extensions, networks with link failures, and quantized communication.
Critically, almost complete totality of the algorithms studied in the literature do not consider the cost of communication among nodes. Instead, nodes are often assumed to communicate information at any precision and at any rate. Given the fact that communication constraints often play a crucial role in practical networks, we wish to precisely analyze the impact of communication constraints on the convergence of the local estimates to the optimal solution.
Ultimately, we wish to be able to characterize the effect of limited communication on a large class of consensus algorithm and ultimately come to a fundamental understanding of the effect of transmission limitations on the distributed optimization. From such deep understanding we hope to be able to come to novel and original problem formulations in the context of distributed optimization which also include the cost of transmitting reliable information across nodes.
Federated learning
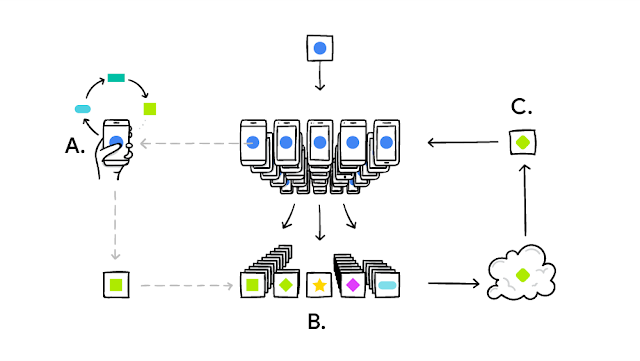
Image Source: https://ai.googleblog.com/
Machine learning algorithms commonly require the access to a large amount of data on a centralized server. For example, language models can improve speech recognition and text entry, and image models can automatically select good photos.
Consequently, training deep models requires the aggregation of a multitude of labeled samples from users, which may contain private data.
As this rich data is often privacy sensitive, large in quantity, or both, which may preclude logging to the data center and training there using conventional approaches.
Federated Learning is a machine learning setting where the goal is to train a high-quality centralized model while training data remains distributed over a large number of clients each with unreliable and relatively slow network connections.
A principal advantage of this approach is the decoupling of model training from the need for direct access to the raw training data. Clearly, some trust of the server coordinating the training is still required. However, for applications where the training objective can be specified on the basis of data available on each client, federated learning can significantly reduce privacy and security risks by limiting the attack surface to only the device, rather than the device and the cloud.
A major bottleneck of federated learning is the transfer of the updated models over the uplink communication link from the users to the server.
Additionally, devices might joint and leave the network at any point, thus requiring the learning algorithm to be robust with respect to random changes in the data availability.
To tackle this learning framework, we proposed various methods for quantizing the data sent from the users to the server. These methods include random masks, subsampling, and probabilistic quantization. The fact that these approaches are suboptimal from a quantization theory perspective, motivates the proposed research on efficient and practical quantization methods for facilitating updated model transfer in federated learning.
Dictionary based string matching
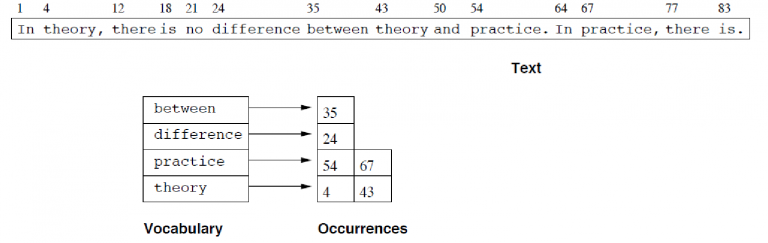
Figure 1: Dictionary-based string matching
The data structure at the core of nowadays large-scale search engines, social networks and storage architectures is the inverted index or posting table, that is the table which stores the position of relevant content in the database or databases. This table is used for the dictionary-based string matching problem, that is the problem of retrieving the position of a query from a system’s user. Because of the huge number of documents indexed by search engines and stringent performance requirements dictated by the heavy load of user queries, the posting lists often store several millions (even billions) of locations and must be searched and ranked for relevance with extreme efficiency so that the most relevant results can be returned in a sub-second times.
Given the relevance of this data structure, the design and performance of the posting table has been extensively studied in the context of information retrieval. Information retrieval is the foundation for modern search engines and studies a number core topics underlying modern search technologies, including algorithms, data structures, compression, indexing, retrieval, relevance ranking and evaluation techniques.
As shown in in Fig. 1, a inverted index table is composed of two elements: the vocabulary and the set of occurrences. The vocabulary is a set of strings which appear in the document while the set of occurrences is a set of integers denoting the positions at which a string in the vocabulary appears in the document. Upon receiving a query from a user, the information retrieval system decomposes the query to a set of strings from the vocabulary, retrieves the set of occurrences and employs an algorithm to determine the position of the query matches in the database. In the context of information retrieval, the research focus is on the concrete technological developments, with special emphasis on text retrieval as web search engines are the heaviest users of information retrieval systems. For this reason, the set of strings in the vocabulary are often chosen as the unique words in a document and the set of occurrences in the posting table are all the occurrences of a word in the text. In such scenario, the retrieval algorithm is a phrase search algorithm which determines the contiguous positions of elements in the set of occurrences corresponding to the vocabulary string as they appear in the query. Although relevant, such settings are often too restrictive and rely on assumptions that do not hold true in all scenarios. For instance, elements in the dictionary are generally considered to be evident, such as words in the English language. Again as in the English language, words in the vocabulary are generally not overlapping, so that storing the position of each word in a document does not employ any redundancy in the inverted index table. Finally, the English text is not compactly described through statistical measures so that the occurrence of letters in the alphabet is not easily described as a statical process. We believe that such assumptions do not hold true in general and that a fundamental reformulation of the problem is necessary in order to more efficiently store a larger set of data. In particular, we wish to employ information theoretical concepts which arise from the data compression literature to formulate the design of the inverse table vocabulary and storing algorithm as a cost minimization problem. For instance, one cost function is the cost of retrieving the set of consecutive indexes given a list of positions in which each element in the vocabulary occurs in the original source. We intend to relax a number of assumptions which are commonplace in the information retrieval system such as (i) the elements in the vocabulary are chosen a-priori and according to some expert advice or context of the data acquisition (ii) elements in the dictionary are non-overlapping in the source sequence, so that no redundant information is stored in the database and (iii) no compact statistical description of the source is possible. Instead, we formulate the statistical dictionary-based as a 3-fold problem: (i) the problem of optimally selecting the codeword in the vocabulary so as to minimize the retrieval cost without imposing any restriction on the set of chosen elements in the vocabulary, (ii) the problem of optimally choosing which matches of the elements in the vocabulary in the source sequence are stored in the posting table and finally, (iii) the problem of determining a consistent and compact description of the probability distributions of the source and the query over which the average retrieval cost can be evaluated.
Comparison-limited vector quantization
Image Source: https://commons.wikimedia.org/
Quantization, that is transforming continuous amplitude values into discrete ones so as to minimize a prescribed distortion measure subject to a output cardinality constraint, is one of the fundamental signal processing operations. As such, quantization has been studied in a number of contexts and a vast amount of results have been derived for this problem.
We consider a variation of this problem so far neglected in the literature that is relevant in the design of low-cost, energy-efficient quantizers.
Vector quantizers are typically manufactured using op-amp comparators that obtain a linear combination of the quantizer inputs and a bias and produce a zero/one voltage whether the comparison between these two signals is positive/negative. Generally speaking, comparators are components with high power consumption and manufacturing cost: for this reason, it is reasonable to evaluate the cost of a quantizer in terms of the number of comparators it requires.
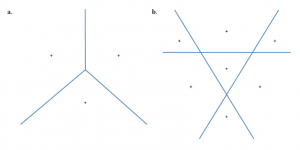
Figure 2: Fig. 1. Schematic representation of: a. a 2-dimensional quantizer with rateR= 1.5 bpsand b. a 2-dimensional quantizer utilizingt= 3comparators
As an example, let us consider the case of a two-dimensional quantizer (d= 2) in which each dimension is quantized with a rate of 1.5 bits-per-sample (R= 1.5 bps). When quantizing a generic source, the three discretization points are separated in Voronoi regions as in Fig. 1.a so that the number of comparators required is k= 3. More generally, since every two reconstruction points are separated by an edge of the Voronoi region, a vector quantizer requires 2R(2R−1)/2 comparators. This scaling of the quantizer cost is generally valid for low-rate quantizer, since in this scenario the number of neighbors of each reconstruction point is large. Given that this quantization regime is naturally associated with low cost devices, the cost scaling seems to be particularly disadvantageous.
A natural question that naturally arises is whether a better scaling of the quantizer cost can be attained. To address this question, note that number of comparators equals the total number of hyperplane segments in the Voronoi regions. Accordingly, the best scaling is attained when the hyperplanes induce the largest number of partitions of the space of dimension d. After some geometrical consideration, one realizes that for the case of d= 2 and R= 1.5, the largest number of partitions is indeed 7 and corresponds to the configuration in Fig. 1.b. It is now apparent that there exists a large gap in the optimal quantizer design whether one considers a constraint on the number of points used in reconstruction or the number of comparators employed by the quantizer.
To study this problem further, we define comparison limited vector quantization problem in its full generality as a variation of the classical vector quantization problem. We also provide a first algorithm for the quantizer design: although not optimal, this first approach investigates the combinatorial geometric aspects of the optimal quantization design problem.
One-bit massive MIMO

Data processing speed, storing and transmission capabilities walk in lockstep, following an exponential rise which shows no sign of decline. Among data transmission technologies, wireless communication has been the most pervasive in recent years, as it allows for a high degree of mobility of the users. While data processing and storage face physical limitations in the dimension of the solid-state circuitry, wireless communication faces limitation in the transmission frequency. As the demand for data transmission rate increases, new services can be allocated only in ever higher electromagnetic frequencies.
At higher transmission frequencies, the shorter wavelengths have increased propagation loss and absorption by obstacles. These unfavorable conditions, can be overcome by the use of multiple transmit and receive antennas, as short wavelengths require smaller antenna form factors. For these reasons, in recent years, the coupling of millimeter wave transmissions and multiple-antenna equipment has emerged as a paradigm capable of delivering a drastic increase in wireless transmission rates.
Wireless devices equipped with multiple antennas pose new design difficulties which are yet to be fully understood from a theoretical perspective. Generally speaking, quantization is the most complex and energy demanding operation, requiring precise frequency, timing, and voltage references. Accordingly, the loss of precision in the quantization is often the key factor which limits performance in multi-antenna systems. This is in sharp contrast with classic single-antenna systems, in which the environmental noise is the main hindrance to communication.
We have recently proposed a novel framework for the analysis of multi-antenna receivers subject to quantization constraints which have uncovered intriguing connections to combinatorial geometry. Our model is described as follow: We considered the transmission scenario in which the antenna outputs are obtained as a linear combination of the channel inputs plus additive noise. The antenna outputs are processed by a set of analog combiners which are connected to a set of threshold quantizers.
In our model, the linear combiners and the threshold quantizers can be configured as a function of the channel between the antenna inputs and the antenna outputs. The set of available configurations can be chosen so as to model specific practical analog receiver capabilities such as: multiple antenna selection, threshold quantization, and multilevel quantization. As the number of the quantizer is fixed, the analog receiver configuration has to be optimally chosen, among the set of available configurations, as to maximize the communication rates. For instance, one antenna output can be quantized by multiple threshold quantizers, thus obtaining a precise description of this value. Alternatively, each antenna output can be quantized with fewer bits, resulting in a rough description of all the outputs. More precisely, the same M quantizers can be used to implement either an (M +1)-level quantizer for a single antenna, obtained by “stacking” M threshold quantizers, or a sign quantizer for M antennas. Through this architecture, we are able to study which receiver configuration, among all the feasible ones, yield the best performance. For instance, are able to show that performing multilevel quantization of one antenna is optimal at low SNR and while sign quantization of many antenna outputs is optimal at high SNR. More importantly, in our analysis have we shown a connection between combinatorial geometry and the constraint MIMO quantization problem by leveraging the fact that each quantizer can be seen as an hyperplane partitioning the transmitter channel space. Through this approach we are able to efficiently design transmission constellation and antenna analog processing that achieve high transmission efficiency.
For this project, we wish to further the study of MIMO channel with output quantization constraints and come to a more complete understanding of performance loss in among different receiver front-end architectures.
Capacity of the channel with phase noise channel
Imperfections in the manufacturing of high-frequency oscillators result in jitter, a deviation of the signal pulses from true periodicity.
Even though improvement in the fabrication techniques guarantees ever more precise oscillators, the quest for available bandwidth pushes telecommunication takes place at ever increasing frequencies ever higher so that jitter is doomed to remain one of the main causes of signal degradation in communication systems.
Jitter is a particularly difficult to study as its effects accumulate over time and cause a drift from periodicity: this is in net contrast with other causes of deterioration in communication systems, such as attenuation and power loss, multipath propagation, and other dispersive effects, whose effect do are uncorrelated in time. The effect of noise processes with limited time correlation on the performance of a communication system is a well-studied topic in the literature: unfortunately, very little is known for processes with memory.
Indeed, it is commonly believed that the presence of memory renders the study of jitter extremely challenging and only limited results are available on this topic in the literature. Despite this, jitter remains a source of degradation in all communication systems and many practical transmission schemes and algorithms have been developed to compensate or mitigate its effects.
Unfortunately, a fundamental understanding of the limiting performance in the presence of jitter is currently unavailable and thus these efforts in developing a practical solution to this problem are not guided by well-understood optimality principles.
For this reason, we investigate the effects of jitter from first principles and determine the ultimate performance guarantees for all scenarios of practical relevance.
Interference mitigation and pre-cancellation

It is a fundamental tenet of wireless communication that in rich radio environments interference is a cause of more performance degradation than what environmental noise. Especially for the downlink infrastructure, which is well-connected and not well-powered, the major factor to limit the overall performance is the presence of neighboring base-stations, macro and femtocells.
Many strategies are employed to deal with interference in wireless networks and many more are currently being investigated for the next generation of mobile services and machine-to-machine communication.
The latest years have seen an explosive increase in both the number of devices and the amount of data transmitted over communication networks: frequency bands have become smaller to accommodate more users over the frequency spectrum; networks have become denser to allow for a higher degree of connectivity. As a result, interference is now omnipresent and it has become the limiting factor in the speed and reliability of modern-day communications.
While the extreme connectivity across devices and the high data traffic amplifies the deleterious effect of the interference across devices, it also represents a possible resource for a better interference management.
A fast and reliable network infrastructure with high computational capabilities can pre-compute the transmitted messages to include some aspects of interference pre-coding and interference management. In fact, the rise of cloud services and coordinated multiple access strategies makes the joint pre-coding of signals a viable and attractive strategy. Unfortunately, our theoretical understanding of interference pre-coding is still unsatisfactory as the limiting performance in many relevant scenarios are still unknown. In particular, only very little is known of the interplay between fading and interference pre-cancellation, fading being the fundamental phenomena characterizing the noise in a wireless environment.
For this reason, in this project, we strive to understand the limiting performance of interference pre-coding and determine the optimal interference management strategies for some relevant communication scenarios.
Rate-limited estimation

Figure 3: conceptual representation of rate- limited estimation
The problem of efficient compression of information has always been one of the core engineering problems. Since compression is effective only when fully exploiting the statistical internal structure of the data, it is often a conduit toward an accurate understanding and modelling of the source of information. For this reason, data compression aids a number of engineering and scientific disciplines such as estimation theory, data transmission and machine learning.
Although many aspects of data compression have been considered in the literature, some fundamental questions still remain open to inquiry.
In particular, the problem of compressing a source in noise remains a topic requiring thorough investigation.
Consider the scenario in Figure 1 in which a sensor observes a source in noise and is required to communicate such observation to a central node to be store or processed. The communication between the sensor and the central node is rate-limited, thus requiring the sensor to process the sensed information and reduce the number of bits required to communicate the observation to the central node. Given that the observations are noisy, the encoder does not necessarily have to optimally compress the observation sequence itself, but rather choose a compression strategy which takes into account the way in which the noise affect the observation.
Also, given computational or connectivity constraint, the sensor might not know the statistic of the source and the noise, but only have partial knowledge of their distribution. This constraint follows from the fact that the practical sensors are usually general purpose and have limited flexibility in their programming and sensing strategy. On the other hand, the central node is computationally more capable and fully programmable and adaptive. In this scenario, the problem arises of how to optimally compress the noisy source observation as to reduce the communication rate between the sensor and the fusion center while making the source reconstruction close to the original sequence. Unfortunately, such problem is not well understood from a theoretical standpoint and the optimal compression strategy for a given class of sources and noises distributions has yet to be identified.
For this reason, our aim is to investigate the relationship between the source and noise knowledge at the sensor and the best possible compression strategy of the noisy observations.